Introduction to patentr
Raoul R. Wadhwa, James Yu, Milind Y. Desai, Jacob G. Scott, Péter Érdi
28 May 2021
Source:vignettes/intro.Rmd
intro.RmdPurpose
Information about patents approved in the United States is publicly available. The United States Patent and Trademark Office (USPTO) provides digital bulk patent files on its website containing basic details including patent titles, application and issue dates, classification, and so on. Although files are available for patents issued during or after 1976, patents from different periods are accessible in different formats: patents issued between 1976 and 2001 (inclusive) are provided in TXT files; patents issued between 2002 and 2004 (inclusive) are provided in XML format; and patents issued during or after 2005 are provided in a distinct XML format. The patentr R package accesses USPTO bulk data files and converts them to rectangular CSV format so that users do not have to deal with distinct formats and can work with patent data more easily.
Installation
CRAN hosts the stable version of patentr and GitHub hosts the development version. Each of the lines of code below install the respective version.
# stable version from CRAN
install.packages("patentr")
# development version from GitHub
remotes::install_github("JYProjs/patentr")Data acquisition
Acquiring patent data from the USPTO is straightforward with patentr’s get_bulk_patent_data function. First, we load patentr and the packages we’ll need for this vignette.
library(patentr)
library(readr) # to input data
library(magrittr) # for the pipe (%>%) operator
library(dplyr) # to work with patent dataThen, we use it to acquire data from the first 2 weeks in 1976. Since patentr stores the data as a local CSV file, we must import the data into R. For this, we use read_csv from the readr package.
# acquire data from USPTO
get_bulk_patent_data(
year = rep(1976, 2), # each week must have a corresponding year
week = 1:2, # each week corresponds element-wise to a year
output_file = "temp_output.csv" # output file in which patent data is stored
)
#> DOWNLOADING TXT FILE 1...PROCESSING...DONE
#> DOWNLOADING TXT FILE 2...PROCESSING...DONE
#> [1] TRUE
# import data into R
patent_data <- read_csv("temp_output.csv")
#>
#> ── Column specification ────────────────────────────────────────────────────────
#> cols(
#> WKU = col_character(),
#> Title = col_character(),
#> App_Date = col_date(format = ""),
#> Issue_Date = col_date(format = ""),
#> Inventor = col_character(),
#> Assignee = col_character(),
#> ICL_Class = col_character(),
#> References = col_character(),
#> Claims = col_character()
#> )
# delete local file (optional - but we no longer need it for this tutorial)
file.remove("temp_output.csv")
#> [1] TRUEWe peek at the patent data to get a glimpse of its structure.
tail(patent_data)
#> # A tibble: 6 x 9
#> WKU Title App_Date Issue_Date Inventor Assignee ICL_Class References
#> <chr> <chr> <date> <date> <chr> <chr> <chr> <chr>
#> 1 03932… Device… 1974-03-22 1976-01-13 Yoshiharu… Pioneer… G11B 210… 3620429;36…
#> 2 03932… Magnet… 1974-06-10 1976-01-13 Emory Hor… <NA> G11B 231… 2778880;37…
#> 3 03932… Superm… 1972-12-29 1976-01-13 Shoichi S… Olympus… G11B 2306 3550983;35…
#> 4 03932… Sound … 1974-09-30 1976-01-13 Franz Sin… Compur-… G11B 1560 3008012;31…
#> 5 03932… Magnet… 1974-03-14 1976-01-13 Nelson K.… Interna… G11B 57… 3005056;32…
#> 6 03932… Revers… 1974-09-10 1976-01-13 Paul F. W… Informa… G11B 58… 2886330;32…
#> # … with 1 more variable: Claims <chr>
str(patent_data)
#> spec_tbl_df[,9] [2,636 × 9] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
#> $ WKU : chr [1:2636] "RE0286710" "RE0286729" "RE0286737" "RE0286745" ...
#> $ Title : chr [1:2636] "Hydrophone damper assembly" "Pliable tape structure" "Method of preserving perishable products" "Catamenial device" ...
#> $ App_Date : Date[1:2636], format: "1974-08-26" "1975-02-06" ...
#> $ Issue_Date: Date[1:2636], format: "1976-01-06" "1976-01-06" ...
#> $ Inventor : chr [1:2636] "James W. Widenhofer" "Alfred W. Wakeman" "Joseph J. Esty" "Linda S. Guyette" ...
#> $ Assignee : chr [1:2636] "Sparton Corporation" NA "U. C. San Diego Foundation" NA ...
#> $ ICL_Class : chr [1:2636] "B63B 2152;B63B 5102" "E05D 700" "B65B 3104" "A61f 1320" ...
#> $ References: chr [1:2636] "2790186;3329015;3377615;3543228;3543228;3711821;3720909;3803540" "1843170;2611659;3279473;3442415;3851353" "2242686;2814382;3313084" "1222825;1401358;1887526;3085574" ...
#> $ Claims : chr [1:2636] "I claim:1. A hydrophone damper assembly comprising, in combination, an elongatedtube of flexible material havin"| __truncated__ "What is claimed is:1. A flexible tape for joining mating edges of adjacent members,said tape having an X-like c"| __truncated__ "Having described my invention, I now claim:1. Those steps in the method of preserving a perishable product in a"| __truncated__ "I claim:1. A rolled cylindrical tampon .Iadd.having means for conducting body fluidto the interior thereof, sai"| __truncated__ ...
#> - attr(*, "spec")=
#> .. cols(
#> .. WKU = col_character(),
#> .. Title = col_character(),
#> .. App_Date = col_date(format = ""),
#> .. Issue_Date = col_date(format = ""),
#> .. Inventor = col_character(),
#> .. Assignee = col_character(),
#> .. ICL_Class = col_character(),
#> .. References = col_character(),
#> .. Claims = col_character()
#> .. )Sample use
For the recently acquired set of patents, let’s say we are interested in how long it took for the patents to get issued once the application was submitted. We can calculate the difference between issue date (Issue_Date column) and application date (App_Date) column, then either obtain a numerical summary or visualize the results as a histogram. The code block below does both.
# calculate time from application to issue (in days)
lag_time <- patent_data %>%
transmute(Lag = Issue_Date - App_Date) %>%
pull(Lag) %>%
as.numeric
# get quantitative summary
summary(lag_time)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 168.0 468.0 601.0 664.1 771.0 9331.0
# plot as histogram
hist(lag_time,
main = "Histogram of delay before issue",
xlab = "Time (days)", ylab = "Count")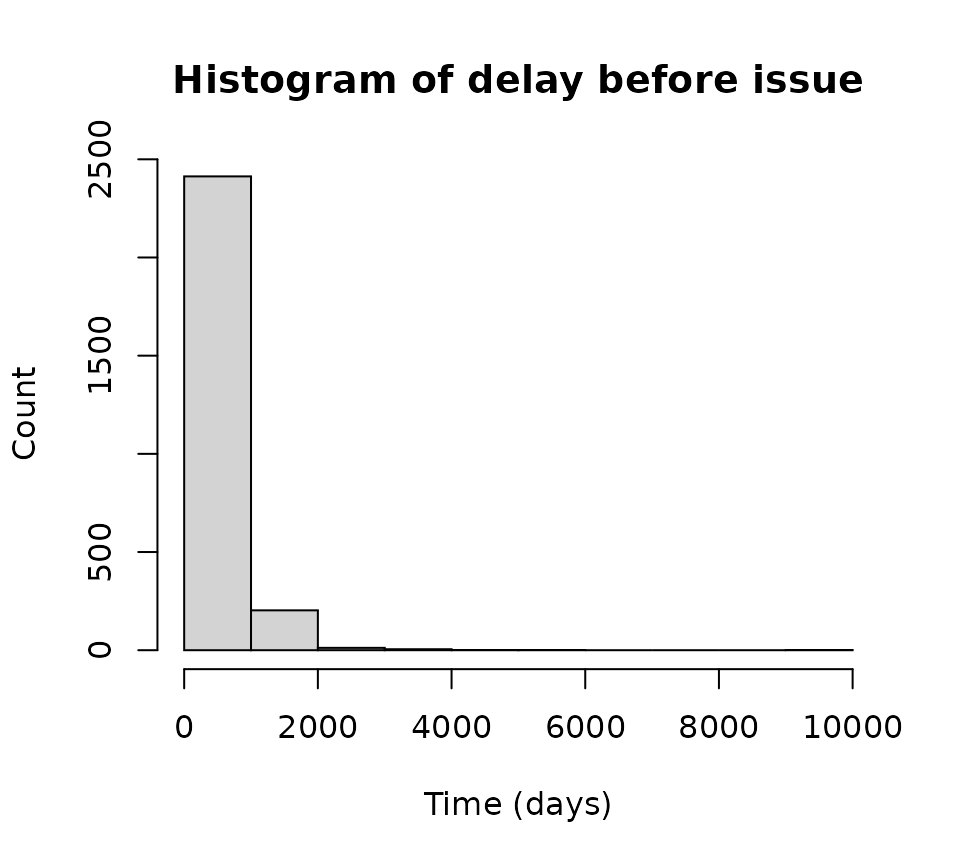
In addition to application and issue dates, the downloaded USPTO data contains multiple text columns. More information about these can be found at https://uspto.gov.